Chapter 3. Significance Tests and Assumptions
I. Significance Tests
We want to test whether the relationships that we see in the sample exist in the population. Note this expression implies inferential statistics. If the null hypothesis about the slope is rejected (in other words, if the p-value is smaller than .05), then we will interpret either  or the standardized slope
or the standardized slope  to determine whether a statistically significant (non-zero) value is large enough (to be substantively important). In other words, if the p-value is not smaller than .05, then we don’t need to interpret or the beta weight .
to determine whether a statistically significant (non-zero) value is large enough (to be substantively important). In other words, if the p-value is not smaller than .05, then we don’t need to interpret or the beta weight .
Also when doing hypothesis tests, some conditions (the so-called “assumptions”) will need to be checked in advance, so we can assess whether our test results are believable.
The simplest hypothesis test using r tests whether the correlation is zero in the population ( ). That is, we want to determine the probability that an observed
). That is, we want to determine the probability that an observed  (= sample statistic) came from a hypothetical null parameter (
(= sample statistic) came from a hypothetical null parameter ( ). In other words, the null hypothesis is the correlation is 0 in the population.
). In other words, the null hypothesis is the correlation is 0 in the population.
Sometimes this t statistic is squared, which results in an F statistic with 1 and n – 2 degrees of freedom (the p-value is the same, regardless of which test is used).
Returning to [Exercise 1], wages and factory workers’ productivity example (see Chapter 1), our r was .65. We can test the null hypothesis that the correlation came from a population in which wages and workers’ productivity are unrelated (where  ).
).
We can compare the t value to a critical value in a t table or look up the p-value using SPSS or Excel. The .05 critical value for  is 2.048. This is when we have only one
is 2.048. This is when we have only one  variable in the model.
variable in the model.
From  ,
,
 for the equation
for the equation  is derived.
is derived.
Since the sample t = 4.53 and the critical value is 2.048, our sample t is greater than the critical t (let us call it  ) and so we reject the null hypothesis that . Also with , the p-value for this statistic is just about .0001. Using Excel we can enter the Excel function “tdist” to get the p-value:
) and so we reject the null hypothesis that . Also with , the p-value for this statistic is just about .0001. Using Excel we can enter the Excel function “tdist” to get the p-value:
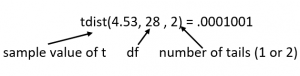
Since we reject the null hypothesis, we conclude that there is a non-zero correlation between wages and workers’ productivity in the population. The  and the squared correlation equals .43, which indicates (based on Cohen’s rules of thumb) that the effect is large.
and the squared correlation equals .43, which indicates (based on Cohen’s rules of thumb) that the effect is large.
The test of the null hypothesis that is the same as the test of the null hypothesis that  (i.e., the parameter estimated by the slope, , is 0), when we have a regression based on only one . (With more this is not the case.)
(i.e., the parameter estimated by the slope, , is 0), when we have a regression based on only one . (With more this is not the case.)
If there is no relationship between and  , then the correlation
, then the correlation  equals zero. This is the same thing as the slope of the regression line
equals zero. This is the same thing as the slope of the regression line  equaling zero, where the line is flat. This flat line also represents a situation where the mean of is the best and only predicted value (
equaling zero, where the line is flat. This flat line also represents a situation where the mean of is the best and only predicted value ( for all cases) and the standard error of the estimate (SEE) will be very close to the standard deviation of .
for all cases) and the standard error of the estimate (SEE) will be very close to the standard deviation of .
What are SEE? SEE is the SD of the residuals (the  ) around the line, also called the root mean squared error. It can be computed in several ways and you do not need to memorize these formulas. Using
) around the line, also called the root mean squared error. It can be computed in several ways and you do not need to memorize these formulas. Using  ,
,  ,
,  and
and  (the number of predictors) as
(the number of predictors) as

Recall that the t-test typically compares an observed parameter to a hypothetical (null) value, dividing the difference by the standard error. The test for was formed in that way (as is the two-sample t for mean differences). Our t-test is  .
.
Here, for a test of we need a standard error (SE) for . It is

SSX is shorthand for the “Sum of Squares of ” which is part of the variance of . The greater the variance of values in your data, the larger SSX will be.

Now let us consider the formula for the SE of the slope ( ).
).
gets smaller when
- SEE gets small – this is the standard deviation of the regression residuals. Better “fit” means smaller SEE and smaller
 gets large – this means we are seeing a larger range of values and that is good – it helps us get a better sense of the value of
gets large – this means we are seeing a larger range of values and that is good – it helps us get a better sense of the value of
- gets large – more data gives us more precision
Recall what the SE of the slope represents.
- is the estimated value of the standard deviation of a hypothetical large set of slopes. (Recall that the SE of the mean of is
 ).
). - is the SD we would get if we sampled repeatedly from the population of interest, and computed a large collection of slopes (
 ) that estimate the same slope .
) that estimate the same slope . - So we would like to be small because it means we have a precise estimate of in our sample.
Let us return to the test. The t-test for comparing to a null parameter (typically  ) is a t-test with
) is a t-test with  ,
,  .
.

Similarly, we can create a confidence interval (CI) around the observed using the following extension of the t-test formula.

If the CI does not capture 0, we would then reject the null hypothesis that our came from a population with 
|
Learning Check
|
 ), SEE (compared to
), SEE (compared to  )
) (want it close to 1) or also
(want it close to 1) or also  (want both to be large) only for simple regression (Since we learn the steps of regression in the section of simple regression, the slope coefficients were placed here; however, they are originally the indicators for an individual slope.)
(want both to be large) only for simple regression (Since we learn the steps of regression in the section of simple regression, the slope coefficients were placed here; however, they are originally the indicators for an individual slope.) (or
(or  if it is a simple regression)
if it is a simple regression)

[Exercise 5]
For the wages and workers’ productivity data, the standard error of is computed below.



(1) If we had 30 participants, how would you compute Sb1 and t statistic? Use the following formulas.


(2) The two-tailed critical t for  with 28 degrees of freedom equals 2.05, so how would you compute the CI? Compute the upper limit (UL) and lower limit (LL). Fill in the blanks.
with 28 degrees of freedom equals 2.05, so how would you compute the CI? Compute the upper limit (UL) and lower limit (LL). Fill in the blanks.
 ( )
( )  2.05
2.05  ( )
( )


(3) Based on the above (2), since 0 does not fall between the LL and the UL, would we reject or not reject the null hypothesis that our came from a population with ?
II. Assumptions in Regression
We will learn about the assumptions needed for doing hypothesis tests. These assumptions involve the residuals from the model, so we need to estimate a model before we can check assumptions. So, we will do some analyses of residuals, and eventually (for multiple regression) we will look for multicollinearity.
In order for our tests to work properly (that is, to reject the null hypotheses the correct portion of the time, etc.) we need to make some assumptions.
1. Assumptions for Tests of and : Linearity
For both correlation and regression, we assume that the relationship between and is linear rather than curvilinear. Different procedures are available for modeling curvilinear data. We can check this assumption by looking at the X-Y scatterplot.
2. Assumptions for Tests of and : Independence
Another assumption of both regression and correlation is that the data pairs are independent of each other. We do not assume is independent of , but rather that ( ,
,  ) is independent of (
) is independent of ( ,
,  ) and (
) and ( ,
,  ) etc.—in general we assume that (
) etc.—in general we assume that ( ,
,  ) for any case
) for any case  is independent of (
is independent of ( ,
,  ) for another case
) for another case  .
.
This means, for example, we do not want to have subgroups of cases that are related—so e.g., if the data are scores on, say, = length of the marriage and = marital satisfaction, we don’t want scores for a sample including husbands and wives who are married to each other.
Unfortunately, there is no statistical or visual test for independence. We simply need to understand the structure of the data. We can find out about independence by knowing how the data were collected. So for instance in the example, I gave, if we knew that only one member of any married couple provided data on = length of the marriage and = marital satisfaction, we might consider the cases to be independent.
Can you think of things that might cause scores on and not to be independent even if data were collected from people not married to each other?
3. Assumptions for Correlation: Bivariate Normality
To draw inferences about the correlation coefficient, we need to make only one assumption in addition to linearity and independence (albeit a rather demanding assumption).
If we wish to test hypotheses about or establish confidence limits on , we must assume that the joint distribution of and is normal. We check this by inspecting the X-Y scatterplot.
4. Assumptions for Regression:
Also, if we wish to draw inferences about regression parameters (e.g., create CIs around or  or test a hypothesis about the value of ), we need to make more assumptions:
or test a hypothesis about the value of ), we need to make more assumptions:
(1) Homogeneity of variances: The error variances are equal across all levels of . The observed variances do not need to be identical, but it is necessary that they could have reasonably come from a common population parameter. If the variances are unequal, then SEE (for which we estimate a single value) is not a valid descriptive statistic for all conditional error distributions (conditional on the value of ).
Usually, we check the homogeneity of error variances by examining error plots (i.e., residual scatter plots). Only if we have a great amount of data can we examine error-variance values at different values of . One typical plot is a scatter plot of or on the horizontal axis and the residuals or even standardized residuals on the vertical axis. We look for a similar spread of points at each place along the horizontal axis. In other words, we are looking for a cloud of points and to see equal spread vertically. We want to be sure we do not see odd patterns in the data. In other words, we do not want to see a fan shape (e.g., more spread for high than low ) or a curvilinear pattern, which suggests something may be missing from the model.
(2) Normality: The distribution of observed around predicted () at each value of (the so-called conditional distributions) are assumed to be normal in shape. This is necessary because we use the normal distribution to lead to the hypothesis tests we do. What we look at here is the normality of the residuals. To check the normality of the residuals we ask for a histogram of the residuals when we run the regression.
(3) Model specification. We need to make the big assumption that the model is “properly specified.” This can be broken into a few pieces:
-
- All important are in the model: Frankly, for the simple regression (just one ) this assumption is most often not true. Can you think of any outcome where only one thing predicts it? Also, some people consider the assumption about linearity to be part of this larger assumption – that is, we can have in the model but if it is not linearly related to the model may still not be properly specified (e.g., we may need
 in the model).
in the model). - No useless are in the model: This part of the assumption says no predictors that are unrelated to are in the model. For the simple regression, this is not really applicable – it will come up when we have several in the model (i.e., for multiple regression).
- All important
As was true for independence there is no single test for model specification. We can evaluate the two parts of the assumption using logic and (eventually) tests of the model. For now, we can only assess the first part, and we can pretty much assume it is false when we have only one . A part of the rationale here is simply to look at the literature in any area and see what the important predictors of your have been discovered to be, to date. One way to suggest this assumption is wrong is to find at least one predictor (other than the one in your model) that relates significantly to .
When we examine multiple regression models we will see how to assess the second part, by deciding whether there are “useless ” in the model.
Meanwhile, here is a brief comparison between population and estimated (sample) models. Note Greek letters represent parameters, while alphabetical letters are statistics:
| Population | Sample |
 |
 |
 |
 |
 |
 |
So far we have seen nearly all of the procedures available to us for regression with one . Many of these will generalize to the case of multiple regression.
|
Learning Check
The residuals are independent and normally distributed with mean 0 and common variance
The |
 relationship: Examine scatterplot of
relationship: Examine scatterplot of  and eliminate nonsignificant
and eliminate nonsignificant  , estimated by MSE): Examine scatterplot with residuals on vertical and
, estimated by MSE): Examine scatterplot with residuals on vertical and  or
or 
 means “is distributed as”, and “iid” means “independent and identically distributed as”.
means “is distributed as”, and “iid” means “independent and identically distributed as”.  stands for Normal, and inside the parentheses are (mean, variance).
stands for Normal, and inside the parentheses are (mean, variance).
[Exercise 6]
We have learned the regression assumptions so far. Explain at least three assumptions about residuals. Separately, discuss at least three assumptions about the X-Y relationship.
Sources: Modified from the class notes of Salih Binici (2012) and Russell G. Almond (2012).
