Chapter 2. Regression
I. Preliminary Analysis
Before going further with regression we will consider the checks needed on the data we hope to use in the model. Later we will learn about how to do significance tests and then how to check assumptions.
(1) Step 1: Inspect scatterplots. We will look for linear relations, outliers, etc.
(2) Step 2: Conduct a missing-data analysis. We will check for missing subjects and missing values.
(3) Step 3: Conduct a case analysis. We will later examine individual cases as possible outliers or influential cases.
(4) Step 4: Consider possible violations of regression assumptions. Here, we will learn about the assumptions needed for doing hypothesis tests.
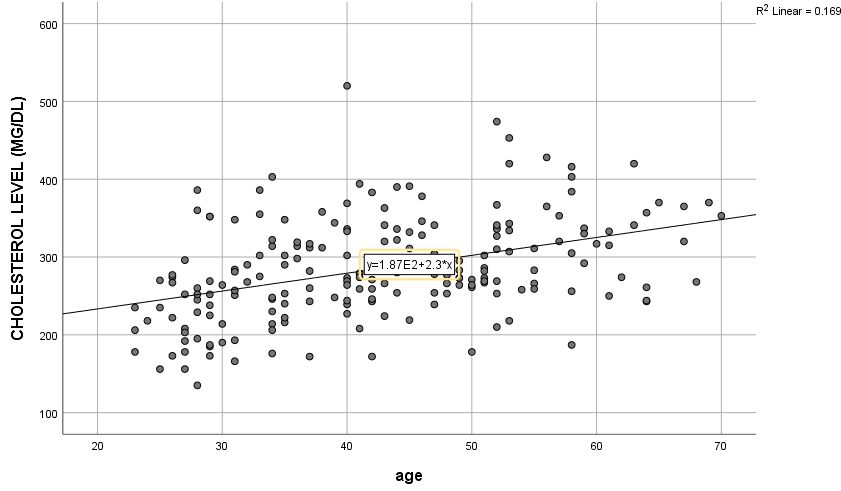
Suppose we have the set of scores shown at right in SPSS (e.g., chapman_1.sav). The correlation between cholesterol and age is  , a moderate value. A scatterplot of the data is shown below. Mostly the relation is linear.
, a moderate value. A scatterplot of the data is shown below. Mostly the relation is linear.
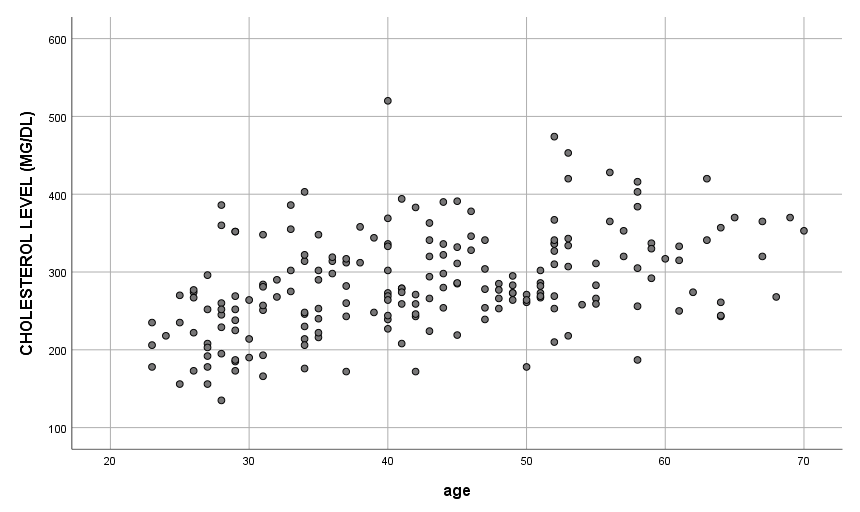
As mentioned earlier, correlation tells us about the strength and direction of the linear relationship between two quantitative variables. Regression gives a numerical description of how both variables vary together and allows us to make predictions based on that numerical description.
1. Inspecting the scatterplot
The scatterplot will show us a few things. Here’s what to look for:
(1) Does the relation look fairly linear?
(2) Are there any unusual points?
(3) How close to the line do most points fall?
Let us now simplify the above plot to explain an unusual point better. One thing you should have noticed is that one point is far from the line and the other points.
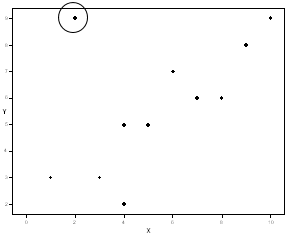
In this data, the relationship is fairly linear (aside from the one point), so we are happy about that. Let us see what happens when that point is removed. Let us compare two regression lines:
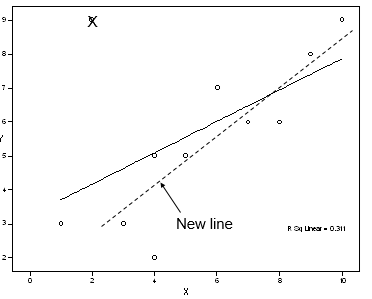
Old values: 
 =.31
=.31  , where MSE is mean squared errors, and
, where MSE is mean squared errors, and
New values:  =.79
=.79 
When the odd point is removed, the slope of the line increases, the  and go up, and MSE drops. The new line has a better fit. Therefore, the inclusion of a point far away from the bulk of the data makes
and go up, and MSE drops. The new line has a better fit. Therefore, the inclusion of a point far away from the bulk of the data makes
- the value drop and
- the line become flatter. Flat lines mean little to no relationship between
 and
and  .
.
Also, we see that the value of shown on the plot (“R Sq Linear”) is much lower.
Points that appear very different from the rest are called “outliers”. We have both visual and statistical ways of identifying outliers. We will learn about the statistical ones in more detail later on, but for now, we can at least look at the plot and look for unusual points. The point we removed was unusual looking and may have been an “outlier”.
In this data, it was a point where the was much higher than we would expect, given the score. Of course, we would want to examine the nature of the data for that case to assess whether there was an explanation for why the point was so unusual.
Caution: Do not just remove points without exploring why they may be unusual!
A point may be an outlier in this simple (one-predictor) model, but it may not look unusual if more variables are added to the model. Therefore, we need to be aware of possible outliers, but we should not permanently delete cases without a good reason until we have explored all models for the data.
2. Missing Data Analysis
Conduct missing-data and case analysis. We’ll check for missing subjects and missing values, and later examine individual cases as possible outliers or influential cases.
Part of what we need to do here is to find out whether cases are totally missing, or are missing some values on the outcome or predictor(s). In particular, if some cases are missing values for , we want to see if cases missing values on appear different from the cases with values for that .
It is difficult to analyze whether cases are missing at random or in some pattern, especially if we have no data for the cases. If we have some data for all subjects we can compare scores of those with complete data to those with some data missing.
However, even if our missing cases have no data at all, sometimes we have data on the population we are sampling and can make a judgment that way. Missing data analysis is another world of statistics, so we can skip it for this moment.
3. Case Analysis
We have already used a plot to see if our data seem unusual in any way. However, there are also statistical ways to analyze all of our cases to see if any cases seem unusual or have more influence on the regression than others.
Typically we will examine the cases in the context of a specific model. We can compute residuals and standardized residuals. Then, what are residuals?
Residuals are the differences between the observed and the predicted (by the model).
Observed

Predicted regression model or estimated regression equation


Subtract  from :
from :

Here  is a residual.
is a residual.
Several kinds of residuals are defined. I will talk about raw residuals and standardized residuals.
First, raw residuals are simply distances from each point to the line:
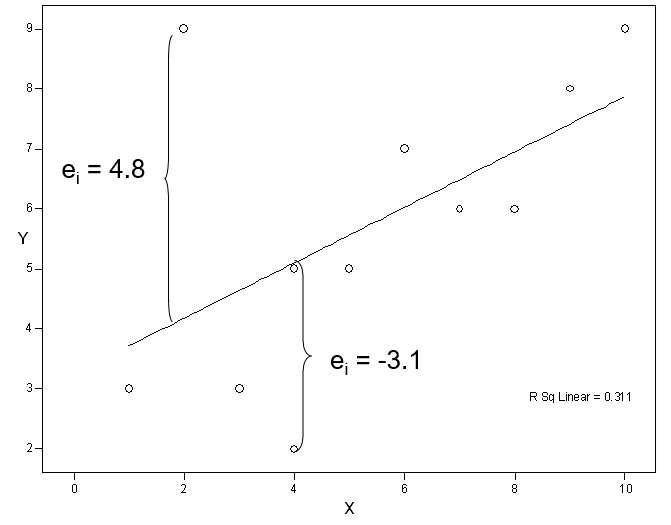
These are easy to interpret because they are in the scale. For instance, if we are predicting GPAs on a 4.0 scale (0 to 4) and a case has a residual of 2, we know that is a large residual. For example, we may have predicted a GPA of 2.0 but the person had a 4.0 (or vice versa if the  ). The unusual case has a residual of nearly 5 points. The next largest residual is just about 3 points and most others are much smaller.
). The unusual case has a residual of nearly 5 points. The next largest residual is just about 3 points and most others are much smaller.
Second, standardized residuals are as follows:

Standardized residuals show the distance of a point from the line, relative to the spread of all residuals. If most points fit close to the line to predict GPA, then a point with a residual of 0.2 may be large.
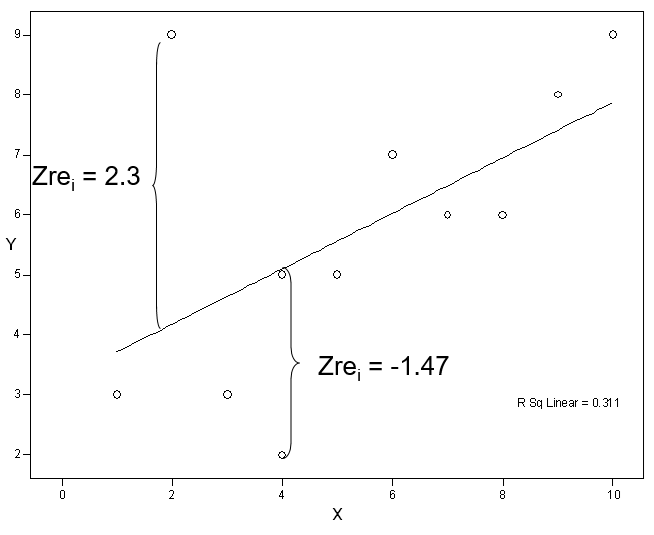
We compute standardized residuals by dividing by their SD (SEE or RMSE = root MSE), so the standardized residuals have a variance or SD of about 1 (SPSS calls these ZRE_n: ZRE_1, ZRE_2, etc.). Here, SEE means standard error of estimate.
Typically we look for ZREs larger than 2 because these are 2 (or more) SDs away from zero. Again the unusual point has a large standardized residual of over 2 SDs. The next largest standardized residual is under 1.5 SDs and no others are above one SD.
We will also see how to use residuals in the consideration of our assumptions – several of our assumptions are about the residuals from the regression line. If these assumptions are not satisfied, we must not run a regression analysis.
4. Checking Assumptions
We will do some analyses of residuals, and (for multiple regression) look for multicollinearity. This section will be later explained in detail.
II. Simple Regression in SPSS
Let us go back to chapman_1.sav that we had seen earlier.
Here is SPSS output for the simple regression analysis.
The following part just tells us what we are using (i.e., age)

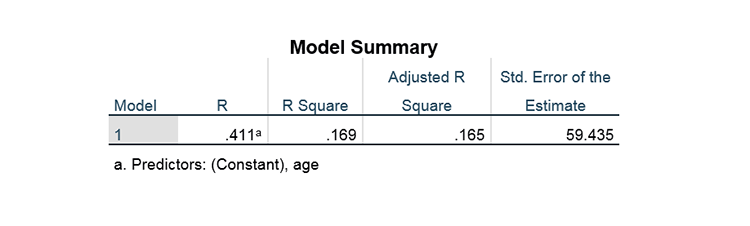
Here we see the  and adjusted for the data as well as the SEE.
and adjusted for the data as well as the SEE.

The correlation r is the correlation between and . However, it is also the correlation between and . Therefore r is telling us about how close the predicted values are to the observed values of . Similarly  or is the square of that value, r. Clearly, we want r to be big and also we want to be big.
or is the square of that value, r. Clearly, we want r to be big and also we want to be big.
When we have several , then will be the correlation between the and predicted values that are based on all of the – so it is a measure that captures more than the set of individual  for the in our model. is called the coefficient of determination.
for the in our model. is called the coefficient of determination.
We can interpret as the proportion of variance in that is explained (= SSR/SST, where SSR is shorthand for the “Sum of Squares of Regression” and SST is shorthand for the “Sum of Squares of Total” ). In other words, is about how well all of the model with the independent variables is working to predict the dependent variable, therefore, we would like to be close to 1. Here, with  we have explained about a third of the variation in scores with this .
we have explained about a third of the variation in scores with this .
Namely, understanding the strength of independent variables (IVs) in predicting the dependent variable (DV) is via the coefficient of determination.
- = SSR/SST = SSR/(SSR+SSE)
- is the proportion of the variation in the DV that can be “explained” by the IVs.
- The maximum value of is 1 (minimum is 0; no negative values).
- SST: Total sum of squared deviations from the mean (i.e., Total variation in Y).
- SSR: Sum of squared deviations from the and Ybar (i.e., Explained variation in Y).
- SSE: Sum of squared deviation from Y and Ybar (i.e., Unexplained variation in Y).
[Exercise 2]
is about how well all of the IVs are working together to predict the DV. With an of .40, this means that 40% of the variation in DV (40% of the DV’s predictability) is explained by all the variables in the model. To understand what other unknown factors might help predict the DV, the researcher would consider what other variables to add to the model.
With an of .40, what percent (%) of the variation in DV is unexplained by all the variables in the model?
With an of .40, can you evaluate if the model predicts the DV well (Refer to Cohen’s rules of thumb below)?
We will learn more about the following table later, but for now, we use it to find the MSE (see the red circle below).
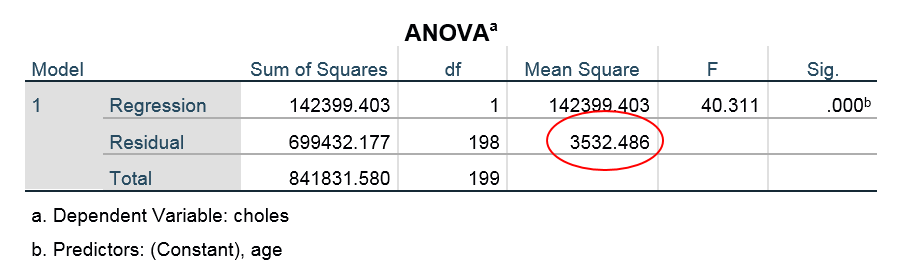
MSE = 3542.486 = 
SEE = 59.435
The MSE (see the ANOVA table) is the “Mean Squared Error” – actually this is the name for the variance of the values around the line. The closer the values are to the line, the smaller MSE will be. It is good for MSE to be small.
We can compare MSE to the variance of . Here the variance of is 4230.31, so our MSE of 3542.486 is a decent amount lower than  .
.
The SEE is just the SD of the  , or
, or  . Therefore, here SEE = 59.435 and can be compared to
. Therefore, here SEE = 59.435 and can be compared to  , which is 65.041. This is telling us the same info as MSE, but SEE is in the score metric (not the squared metric). You can guess – SEE should also be small.
, which is 65.041. This is telling us the same info as MSE, but SEE is in the score metric (not the squared metric). You can guess – SEE should also be small.
The following table contains the slope  and Y-intercept
and Y-intercept  as well as t-test of their values.
as well as t-test of their values.
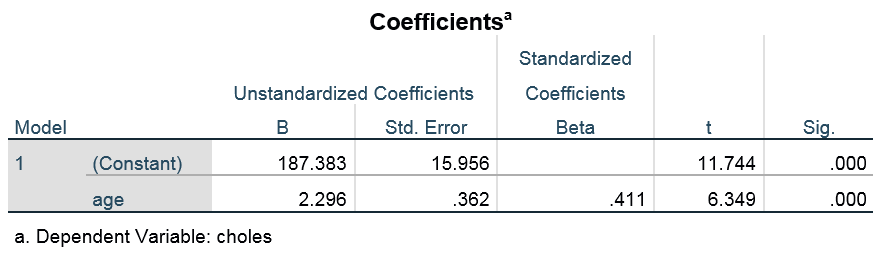
Based on the above table, an estimated regression model is written. We can call it a regression equation or regression line:  , where is the expected value for the dependent variable.
, where is the expected value for the dependent variable.
As shown in the above scatterplot, SPSS computed it as
 , where is an independent variable, which is age, and is cholesterol level.
, where is an independent variable, which is age, and is cholesterol level.Let us interpret Y-intercept from the above table. Here is a generic regression equation:  .
.
 is called the Y-intercept.
is called the Y-intercept.- is the expected value of when
 .
. - This value is only meaningful when can have a realistic value of zero.
Expected cholesterol level 
Plug the estimated value that the Coefficients table has in the equation (i.e., 187.383):
Expected cholesterol level = 187.383 + 2.296*age
- tells us that the expected cholesterol for patients at age 0 is 187.383.
- First, what do you think of age 0? The average mean cholesterol level at age 0 is actually 70 (American Committee of Pediatric Biochemistry, 2019).
- Second, the approximate value 187 on the Y-intercept is telling us that the patients’ cholesterol level would be 187 on average when age is 0. Therefore, for this case, treat this Y-intercept as one point on the regression line, but not one that is very relevant.
Now, let us interpret regression coefficient or slope from the above table. Here is a generic regression equation: .
 is called the regression coefficient.
is called the regression coefficient.- is the expected change/difference in for a one-unit increase in .
- Direction: Look at sign in front of .
- Strength: The higher the value of , the more responds to changes in .
Expected cholesterol level
Plug the estimated value that the Coefficients table has in the equation (i.e., 2.296):
Expected cholesterol level = 187.383 + 2.296*age
- As the age of a patient increases by 1 (say, from 21 to 22), their cholesterol level increases by 2.296.
- For each one-unit increase in age, patients’ cholesterol level increases by 2.296.
III. Standardized Slopes and Regression Model Tests
Earlier, we estimated the regression model. Here we get the values of and plus other indices we saw earlier (MSE, SEE), and also standardized slopes.
1. The F-Test for the Overall Model
We test the overall relationship using the F test. We learn how to test whether the model as a whole (the set of  taken together) explains variation in (the omnibus test = Overall test). If the overall relationship is significant, then, continue with the description of the effects of individual .
taken together) explains variation in (the omnibus test = Overall test). If the overall relationship is significant, then, continue with the description of the effects of individual .
For the test of significance of the overall relationship – a test of  or technically of
or technically of

that is, a test of whether the outcome and predicted values are related. While in practice we test the overall model quality (i.e., F-test) before testing individual slopes. When we do the F test we want it to be large. We make the test as F = MSR/MSE. Also, F = SSR/MSE when we have one . We want SSR or MSR to be large, and MSE to be small. Both of those lead to a large F test.
So how do we do the F test? Let us use our chapman_1.sav data and compute
F = MSR/MSE = SSR/MSE = 142399.403/3532.486 = 40.311
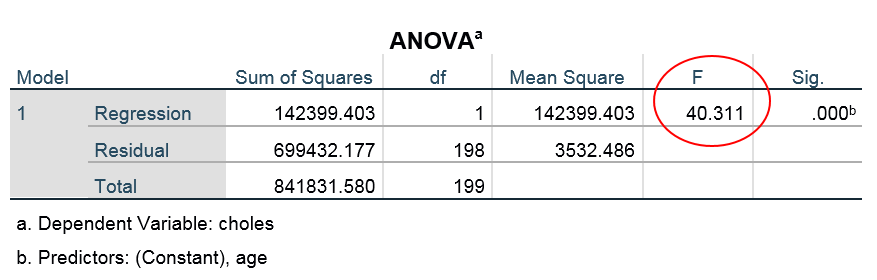
Then use the F table with the right df. In our original example, we have F(1,198). The F table in most statistics books shows that the critical value for the .05 test is 2.705. Our F is above the critical value, therefore, we reject  . Also the printed
. Also the printed  which gives the same decision.
which gives the same decision.
Now, how do we interpret the F test? For our champan_1.sav data we reject , which we said was either:
 (or
(or  because this is a simple regression model)
because this is a simple regression model)
therefore,
 (or
(or  )
)
The value F = 40.311 would occur less than 5% of the time if either of these was true, and that is too unusual. So we decide probably these is not reasonable. In other words, our probably predicts very well, so we decide has a nonzero slope  thus predicts , or the predicted values relate to the actual
thus predicts , or the predicted values relate to the actual  .
.
2. The T-Test for the Individual Slope Tests
We have the test of whether a slope is zero. For the test of significance of the individual slope – a test of is conducted. So far we have only one , so the test of  (the t-test) will give the same decision as to the overall F test. Of course, the individual slope tests in multiple regression model are different from the overall F test.
(the t-test) will give the same decision as to the overall F test. Of course, the individual slope tests in multiple regression model are different from the overall F test.
We want to test whether the relationships that we see in the sample exist in the population. Many students often think that the job of researchers is to prove a hypothesis is true, but very often, they do the reverse: They set out to disprove a hypothesis, which is called a “null hypothesis”. Whether we reject the null hypothesis or not is usually decided with a 5 percent chance of being right. Namely, if we find that the odds of observing the data is less than 5 percent, then we could reject it.
A statistical hypothesis testing does not determine whether the null hypothesis or an alternative hypothesis is correct. This is a matter that can be answered only by knowing the true parameter,  . We do not know the true value because inferential statistics are based on the results of examining only the sample, not the entire population.
. We do not know the true value because inferential statistics are based on the results of examining only the sample, not the entire population.
The hypothesis test is only to find out whether the alternative hypothesis can be said to be correct when looking only at the sample results. The hypothesis test is not to analyze whether the null hypothesis can be said to be right. The null hypothesis is only an auxiliary hypothesis used to find out whether the alternative hypothesis can be judged correct.
Note your estimate of the population parameter may not be so good if your sampling design is not good. This issue is different from statistical analysis (You will learn about the sampling strategies in PUAD629). Researchers can develop the null hypothesis (i.e., ), which means that we believe that there is no relationship between and . By virtue of you decide to conduct the study, you will always have a research (or alternative) hypothesis, which means that we believe that there is a relationship between the and the .
Before we examine any tests, we will stop to consider how to decide if a slope is important. The importance here is independent of statistical significance – this relates to practical importance and to what is known about the outcome in the literature or in terms of theories. Also, we draw on conventional “rules of thumb.”
You may do this when comparing two different models (e.g., for two different variables), and in multiple regression, we will eventually want to choose among the predictors in one model to identify the most important (i.e., compare the magnitudes of s).
To do this we use the standardized regression equation. The slope depends on the scale of the variable as well as that of . Therefore, if we want to compare slopes, we need to be sure they represent variables on the same scale. Unless two s have the same scale, we cannot compare their slopes.
Therefore, we need to equate the scales of the s. Note that, with the same logic, we would not able to compare the magnitudes of weight and height variables in raw scales because they use different scales, but once we standardize them, we can compare the magnitudes of these on because standardized variables can be compared each other.
In sum, once we see whether or not the regression coefficients (i.e., unstandardized coefficient) are statistically significant, then we would like to see standardized coefficients because we want to compare the magnitudes of the significant variables on the outcome. Here, the standardized coefficients are called beta-weights.
The beta-weights are about how well independent variables are pulling their weight to predict the dependent variables. Beta-weight is the average amount by which the dependent variable (DV) increases when the independent variable (IV) increases one standard deviation, controlling for all other IVs (held constant).
Think of multiple regression that has multiple s. We want to compare the magnitudes ofs and to choose which one is the most important on . We use beta-weight for it because it is scale-free.
We interpret beta-weight as follows: When (i.e., IV) changes (either increases or decreases) by one SD, the y-hat (i.e., estimated DV) changes by beta-weight SD, holding the other variables in the model constant.
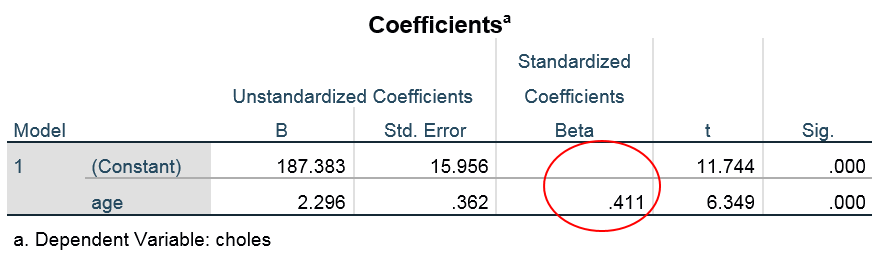 We say the standardized slopes (
We say the standardized slopes ( ) is “the predicted number of standard deviations of change in , for one-standard-deviation unit increase in
) is “the predicted number of standard deviations of change in , for one-standard-deviation unit increase in  ” So if
” So if  we predict that will increase by .411 of a SD, when increases one SD.
we predict that will increase by .411 of a SD, when increases one SD.
In contrast, regression coefficients are expressed in the units of measurement of Y-hat (estimated DV), and the units may not be comparable (e.g., age and blood pressure predict cholesterol but how can you compare the strengths between age and blood pressure because they have different units?). To make the scales comparable we compute a new score:

where we subtract from each  the mean and divide by the SD of . Recall that Z scores always have mean 0 and variance 1.
the mean and divide by the SD of . Recall that Z scores always have mean 0 and variance 1.
If we do this for all the (and  ) the slopes computed based on those new Z scores will be comparable.
) the slopes computed based on those new Z scores will be comparable.
For single-predictor models this gives us a very simple equation:

where is the so-called “beta weight”. Note the intercept is 0 because both  and
and  have means of 0.
have means of 0.
We might also write the formula for the standardized regression line. As before we need to put a hat over the outcome to show it represents a predicted value.

where  = The predicted standardized score on
= The predicted standardized score on  for case
for case  .
.
= the “beta weight” or “standardized coefficient”, the number of standard deviations of change predicted in for one standard-deviation increase in .
 = The standardized score on for case .
= The standardized score on for case .
One last thing is true of beta weights in one-predictor regressions. That is, the standardized regression slope is equal to the correlation of with in simple regression model. Therefore,  for the equation . However, a standardized coefficient is not equal to the correlation between and when we get to the multiple regression context.
for the equation . However, a standardized coefficient is not equal to the correlation between and when we get to the multiple regression context.
Meanwhile, for bivariate (one-predictor) regression we can use rules of thumb for correlations to help interpret the sizes of the beta weights. Jacob Cohen (1988) provided a set of values that have been used to represent sizes of correlations, mean differences, and many other statistics (the so-called “Cohen’s rules of thumb”). These came from evaluations of the power of tests – but they have been widely used in social sciences in other situations.
For correlations, beta weights with only one , and the values are
| r or b* |
r2 | |
| small | .10 | .01 |
| medium | .30 | .09 |
| large | .50 | .25 |
Generally, we evaluate if a slope or a model predicts the DV well, according to Cohen’s rules of thumb.
[Exercise 3]
Read Zimmer’s article (2017), Why We Can’t Rule Out Bigfoot. Discuss how the null hypothesis can keep the hairy hominid alive in terms of falsifiability.
[Exercise 4]
Fill in the blank: We learned that the standardized slopes ( ) is “the predicted number of standard deviations of change in , for one-standard-deviation unit increase in ” So if  we predict that will increase by ( ) of a SD, when increases one SD.
we predict that will increase by ( ) of a SD, when increases one SD.
Sources: Modified from the class notes of Salih Binici (2012) and Russell G. Almond (2012).
